Performance Optimization Guidelines For MS SQL Database
Speed is an important factor for the usability of a website. To retain its users, any application or website must run fast. The overall performance of any app is largely dependent on database performance. Database optimization involves maximizing the speed and efficiency with which data is retrieved.
This article will cover performance improvement guidelines for MS SQL server database.
Indexes:
Indexing is an effective way to tune your SQL database that is often neglected during development. In basic terms, an index is a data structure that improves the speed of data retrieval operations on a database table by providing rapid random lookups and efficient access of ordered records. Setting up indexes usually doesn’t require much coding, but it does take a bit of thought.
Consider creating indexes on columns frequently used in the joins, WHERE, ORDER BY, and GROUP BY clauses. Such columns are the best candidates for indexes against which you are required search particular records.
Create Clustered Indexes: Since a table can have only one clustered index, you should choose the columns for this index very carefully. Analyze all your queries, choose most frequently used queries and include into the clustered index only those columns which provide the most performance benefits from your creation.
Create Non-Clustered Indexes: You should consider non-clustered index creation carefully because each index can take up disk space and has impact on data modification.
Rebuild Indexes Periodically: While you update, delete and create records in your tables, your indexes becomes fragmented and performance may degrade over time. You should consider rebuilding indexes periodically in order to keep performance at the best level.
Use Covering Indexes: A covering index is an index that includes all the columns referenced in the query. Covering indexes can improve performance because all the data for the query is contained within the index itself and only the index pages not the data pages will be used to retrieve the data.
Filtered Index: A Filtered Index is nothing but a Non Clustered Indexes along with Where Clause. Because of this where clause, indexing will be done on portion of records

Data Archiving: It is a process of removing selected data records from operational database that are not expected to be referenced again and storing them in an archive data store where they can be retrieved if needed. There is no built-in command or tool for archiving databases.
Table Partitioning: It is a way to divide a large table into smaller, more manageable parts without having to create separate tables for each part. Data in a partitioned table is physically stored in groups of rows called partitions, which makes it easier to fetch records and requires fewer table scans and as a result the response time is also less and memory utilization is less. Data in a partitioned table is partitioned based on a single column, the partition column, often called the ‘partition key’. It is important to select a partition column that is almost always used as a filter in queries.
When the partition column is used as a filter in queries, SQL Server can access only the relevant partitions.
Let’s take example of Invoices table containing data from every day in 2015, 2016, 2017 .If we partition the table on date column and make separate partition for each year then all rows with dates before or in 2015 are placed in the first partition, all rows with dates in 2016 are placed in the second partition, all rows with dates in 2017 are placed in the third partition.

While executing above query, only second partition will be scanned.
Evaluate Query Execution Plan: Understanding the actual plan that runs is the first step toward optimizing a query. Its main function is to graphically display the data retrieval methods chosen by the SQL Server query optimizer. In SQL server management studio, you’ll see two options related to query plans –
- Display Estimated Execution Plan (Ctrl + L)
- Include Actual Execution Plan (Ctrl + M)
Enable the Display Execution Plan option, and run your query against a meaningful data load to see the plan that is created by the optimizer.
Evaluate this plan and then identify any good indexes that the optimizer could use. Also, identify the part of your query that takes the longest time to run and that might be better optimized.
You might see a detected missing index in execution plan. To create it, just right click in the execution plan and choose the “Missing Index Details…”.
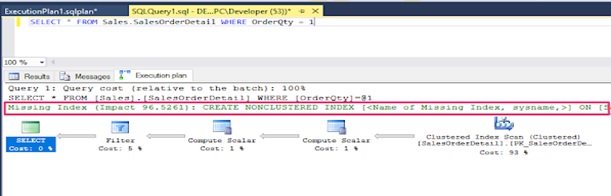
Query Optimization Guidelines:
- Use parameters in queries
The SQL Server query optimizer keeps recently used query plans in memory. When you are not using parameters, the parameters themselves contribute to make queries different from each other, and therefore, the Query Optimizer will not reuse them. Using parameters, the number of query plans in memory will decrease and they will more likely be reused. - Retrieve only the data you need
Sometimes you may be tempted to use SELECT * FROM … when writing your queries, this way you will retrieve all fields in a table when you only need some. In order to reduce the size of transferred data you should specify the list of just the columns you need. - Prefix schema names
Always prefix object names (i.e. table name, stored procedure name, etc.) with its schema name.
Reason: If schema name is not provided, SQL Server’s engine tries to find it in all schemas until the object finds it.
Inefficient – Select * from Employee
Efficient – Select EmployeeId, Name, Salary from dbo.Employee
- Use Locking Hints to minimize locking
Within transactions, use the “WITH NOLOCK” option when possible. The NOLOCK table hint allows you to instruct the query optimizer to read a given table without obtaining an exclusive or shared lock - Choose the smallest data type that works for each column
Explicit and implicit conversions may be costly in terms of the time that it takes to perform the conversion itself. Unicode data types like nchar and nvarchar take twice as much storage space compared to ASCII data types like char and varchar. - Limit the use of cursors
Cursors can result in some performance degradation. We can avoid cursors by
Wise use of joins 2.While loop 3.User defined functions - Avoid Correlated SQL Subqueries
Correlated subquery is one which uses values from the parent query. This kind of SQL query tends to run row-by-row, once for each row returned by the outer query, and thus decreases SQL query performance Inefficient- Efficient-
Efficient-
- Use EXISTS() instead of count while checking existence of record This SQL optimization technique concerns the use of EXISTS(). If you want to check if a record exists, use EXISTS() instead of COUNT(). While COUNT() scans the entire table, counting up all entries matching your condition, EXISTS() will exit as soon as it sees the result it needs.


- Keep database administrator tasks in mind
Do not forget to take database administrator tasks into account when you think about performance. For example, consider the impact that database backups, statistic updates, index rebuilds have on your systems. Administrator should keep an eye on disk space, connection pool, size of backup and log files. Include these operations in your testing and performance analysis.
SQL server hardware should not be shared with other services
Conclusion: The guidelines discussed here are for basic performance tuning. If we follow these steps, we may get good improvement on performance. To do advanced SQL server performance tuning we would need to dig much deeper into each of the steps covered here.



