Web Crawler is an automated script or program that is designed in order to browse World Wide Web in a systematic and methodological way. The whole process executed through Web Crawler is known as web Spidering. Web Spidering, also known as Web indexing is a method to index context of websites by searching browsing World Wide Web. The purpose of web crawling is to provide up to date information in search results. Google and other search engines use web crawling in order to provide updated results.
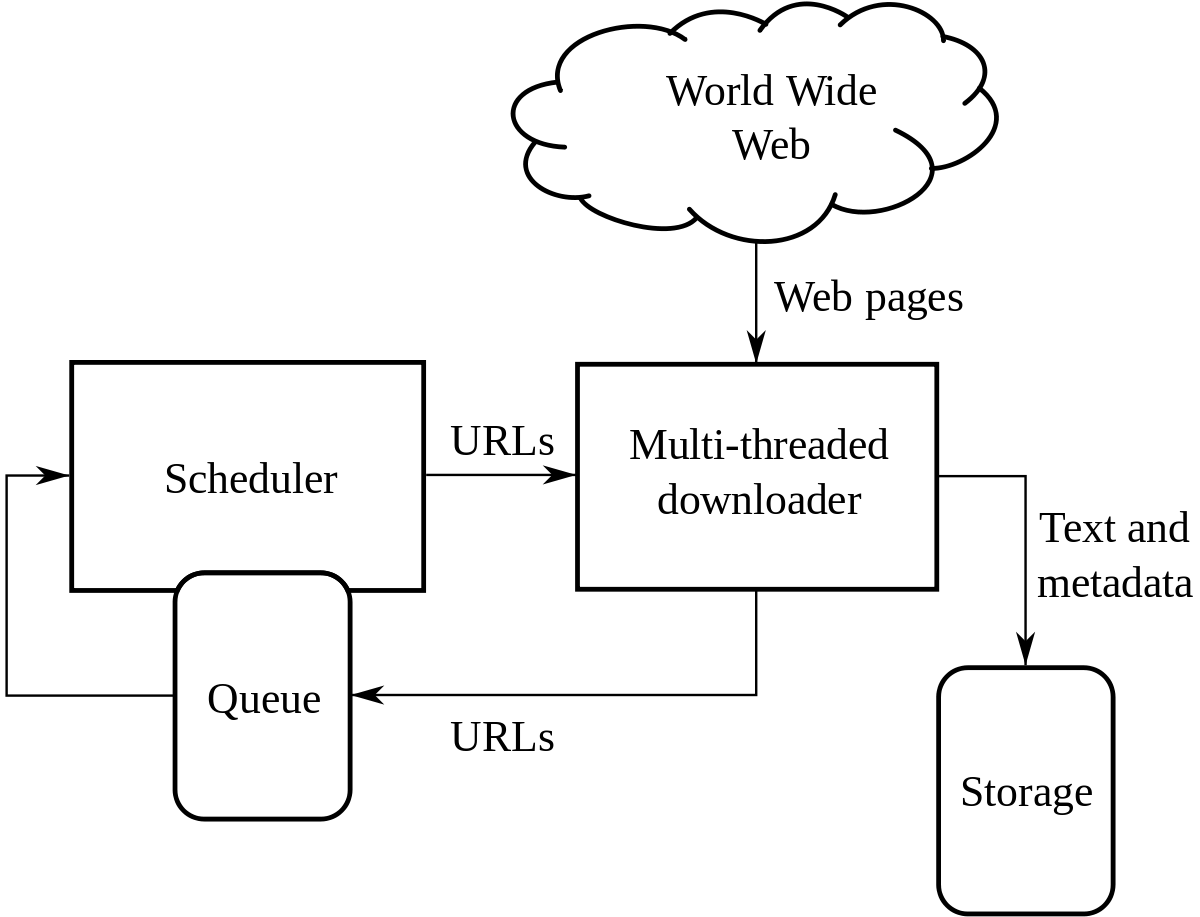
Getting a Deep Insight of Web Spidering:
The basic job of web crawler is to visit different web pages and gather information. The information is later updated into the index entries of the respective search engines. The web crawlers create a copy of the page they have visited and when they return home, they update the pages into the index entries. This is done in order to give latest search results. Apart from search engines, many websites use it in order to be relevant in the search list. Many of the websites use crawlers in order to provide latest and relevant resources to the searcher.
What are Web Crawlers?
Web Crawlers are the ones who read all the pages of the websites they are destined to visit. Their job is to make a copy of the page visited, download the info and then later update it with the index. They are the sole reason for the survival of giant search engines but they have their side effect as well. Web Crawlers also misuse this method spidering by collecting information like email address, address, contact info and other private information and then they use it to spam and do other mischiefs with it. They can consume lots of bandwidth pushing your website to slowing down and temporary shutdown.
How to Control Them?
Though the popular crawlers add to your advantage but there are many that are for ugly purpose and you should avoid them completely. They can cause inconvenience for visitors by slowing down the server speed, temporary slowdown, spamming your mail, stealing data and many more. Recaptcha from Google is used in order to avoid robotic crawlers and it helps a lot. You can use images while mentioning your contact details so that crawlers can’t access it. These two methods can ensure major control. Apart from these, there are many other methods used to control crawlers.
Web Spidering has both advantages and disadvantages. It is up to you how you deal with it to your advantage by avoiding maximum cons.



