Generative AI (GenAI) has captured the imagination, offering the potential for transformative user experiences. However, a key hurdle remains ensuring the accuracy and reliability of responses. Traditional GenAI models often rely on vast amounts of publicly available data, which may not be up-to-date or specific to an organization’s needs. Additionally, they lack access to the rich trove of private data held within an enterprise.
This is where the Retrieval-Augmented Generation (RAG) framework steps in. RAG acts as a bridge, seamlessly integrating private enterprise data with publicly available information. By retrieving the most relevant information for each user query, RAG empowers GenAI models to generate responses that are not only accurate but also highly contextual and personalized.
In this blog post, we’ll delve into the world of RAG. We’ll explore its core components, the undeniable benefits it offers businesses of all sizes, and how it’s revolutionizing real-world applications of GenAI.

Understanding the Need for RAG: Accurate Information Retrieval in the Age of Gen AI
The rise of Generative AI (GenAI) has ushered in a new era of human-computer interaction (HCI). From chatbots that answer customer queries to AI assistants that streamline workflows, GenAI holds immense potential to transform various industries. However, a critical challenge remains ensuring the accuracy and reliability of information GenAI models provide.
Here’s why the need for a framework like RAG becomes crucial:
- Limitations of Public Data: Traditional GenAI models heavily rely on vast datasets of publicly available information. While this data provides a broad knowledge base, it can be:
- Outdated: Public data may not reflect the latest information, leading to inaccurate or misleading responses.
- Lacking Specificity: Public data often lacks the specific context and domain knowledge relevant to an organization’s unique needs.
- Inaccessible Private Data: GenAI models typically struggle to access and leverage the rich trove of private data held within an enterprise. This valuable data can include:
- Internal Documents: Company reports, customer records, and internal communications are a goldmine of specific and up-to-date information.
- Domain Expertise: Enterprise data often captures the specific knowledge and expertise relevant to an organization’s industry or operations.
These limitations hinder GenAI’s ability to deliver consistent, trustworthy, and truly valuable responses. Imagine a customer support chatbot relying on outdated public data – it could provide inaccurate product information or miss crucial details specific to the company’s services.
What is Retrieval Augmented Generation (RAG)?

Retrieval Augmented Generation (RAG) blends the deep comprehension and text generation skills of language models with the extensive, specialized knowledge within an organization. It achieves this by merging two key processes: retrieval and augmented generation. In the retrieval phase, the system searches through documents to find information relevant to the user’s query. During augmented generation, it uses this retrieved information to produce text, leveraging large language models (LLMs) or task-specific models that follow instructions.
Core Components of RAG-
1. Language Models (LLMs):
Large Language Models (LLMs) are powerful neural networks trained on massive datasets of text and code. These models excel at understanding and generating human-like text, making them ideal for tasks like question answering and creative text formats. Within the RAG framework, LLMs form the core engine for response generation.
Foundation Models in RAG
While various LLMs exist, the RAG framework can be implemented with several prominent models like GPT-4 from OpenAI, Claude 3.5 from Anthropic AI, or LLMA-3 developed by Meta. These pre-trained models boast vast knowledge bases and the ability to understand complex language structures, making them well-suited for the demands of RAG. Each LLM may have its own strengths and weaknesses, and the optimal choice for a specific application might depend on factors like training data, performance benchmarks, and computational cost.
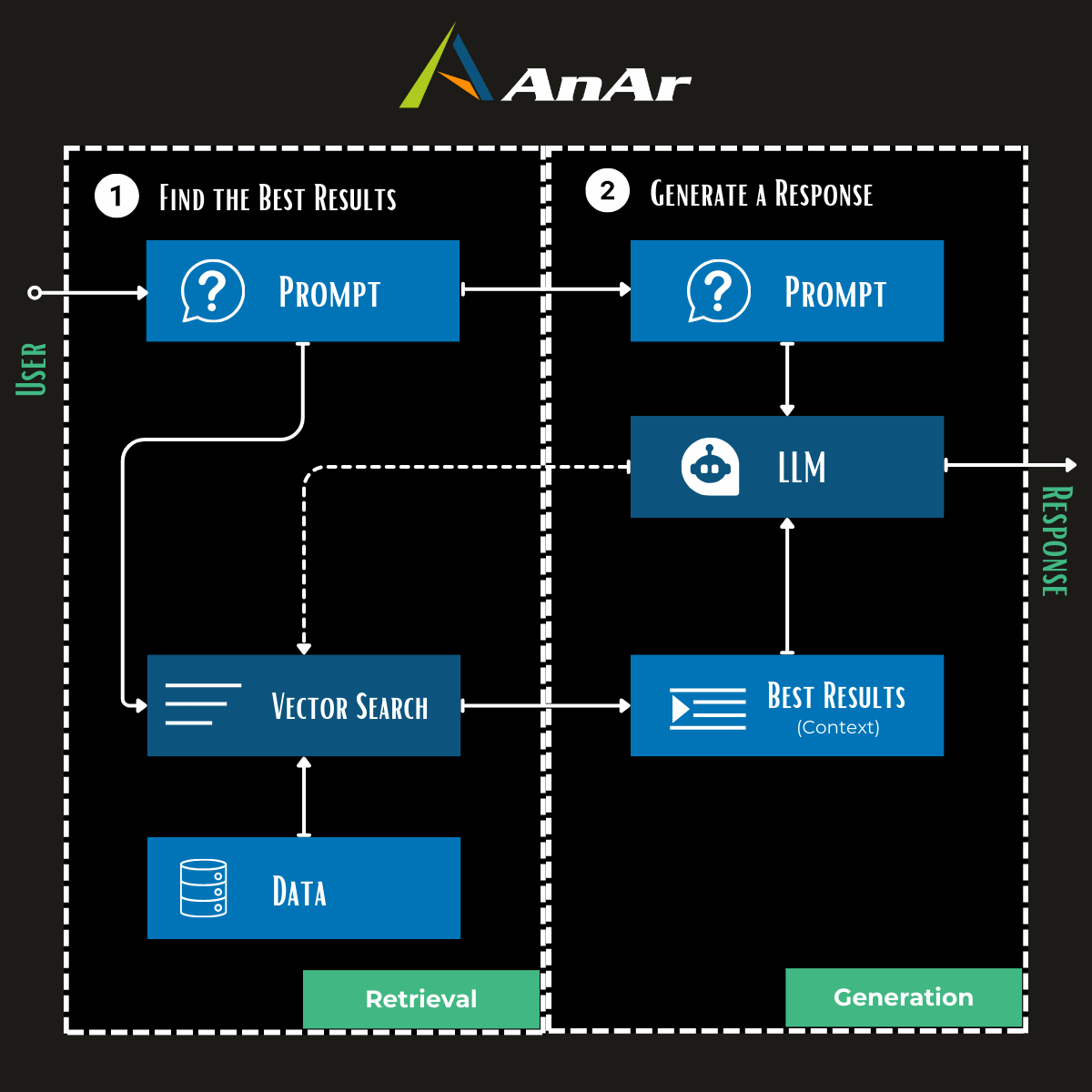
2. Relevant Document Retrieval:
Why Relevant Documents Matter?
Imagine a chatbot tasked with answering customer queries. If it relies on irrelevant information, its responses will be inaccurate and misleading. This is why RAG prioritizes the retrieval of relevant documents for each user query. Relevant documents provide the LLM with the specific information needed to generate accurate and informative responses.
How RAG Retrieves and Prioritizes Documents:
- Understanding User Queries: The first step involves analyzing the user’s query. RAG’s information retrieval system employs natural language processing (NLP) techniques to grasp the intent and context behind the user’s words. This helps identify the specific information required for an accurate response. For example, the query “best laptops for students” might require information on affordability, performance, and durability.
- Targeted Information Search: Using the analyzed query as a guide, RAG searches through its vast knowledge base. This base can include publicly available information like online articles and Wikipedia entries, alongside an organization’s private data (internal documents, customer records, etc.).
- Prioritizing Relevant Sources: Not all retrieved information is created equal. RAG employs ranking algorithms to prioritize the most relevant and reliable sources. These algorithms consider factors like:
- Keyword Matching: Documents containing keywords directly related to the user’s query are ranked higher.
- Contextual Alignment: Documents that align with the broader context of the query, such as the user’s domain or past interactions, are prioritized.
- Source Credibility: The reliability and trustworthiness of the information source are factored in.
By prioritizing these elements, RAG ensures the LLM has access to the most relevant and accurate data for generating high-quality responses.
3. Enhanced User Query Understanding:
Why Understanding User Intent is Crucial?
Understanding the true intent behind a user’s query is paramount for effective information retrieval. Consider a query like “How do I get a refund?” While the literal meaning is clear, the user’s intent might be to find the organization’s return policy or initiate a refund process.
How RAG Processes and Interprets User Queries:
- Intent Recognition: RAG utilizes advanced NLP techniques to go beyond just keywords and identify the underlying intent behind a user’s query. This allows RAG to retrieve information specific to the user’s true goal.
- Contextual Awareness: RAG doesn’t operate in a vacuum. It considers the broader context surrounding the user’s query. This can include the user’s past interactions with the system, the domain of the query (e.g., customer support, product information), and any other relevant organizational information. By understanding the context, RAG can refine its information retrieval process and ensure it retrieves the most relevant documents for a comprehensive response.
What are the benefits of RAG in Generative AI?
Integrating Retrieval-Augmented Generation (RAG) into generative AI models significantly enhances performance and reliability:
Improved Factual Accuracy and Reduced Hallucinations
Factual Accuracy: RAG enhances factual accuracy by sourcing up-to-date documents during the retrieval step, ensuring responses are grounded in current, factual data.
Reduced Hallucinations: By leveraging reliable sources, RAG minimizes the generation of incorrect information, producing more accurate and trustworthy outputs.
Enhanced Personalization and Relevance of Responses
Personalization: RAG tailors’ responses to specific user needs by dynamically retrieving relevant information, improving user satisfaction and engagement.
Relevance: Combining retrieval with generation, RAG ensures responses are highly relevant, matching user queries with the best documents and synthesizing them into coherent answers.
Transparency and Trust Through Data Grounding
Transparency: RAG promotes transparency by showing the sources of information used, allowing users to verify and trust the AI’s outputs.
Data Grounding: RAG anchors AI-generated content in verifiable sources, ensuring outputs are based on solid evidence and fostering greater user trust.
Top RAG Use Cases in the Enterprise
Retrieval-Augmented Generation (RAG) offers numerous applications within enterprise environments, significantly enhancing both internal and external operations. Here are some of the key use cases:
Internal RAG Use Cases
Employee Productivity Apps: Streamline workflows by quickly retrieving relevant internal information, improving decision-making and efficiency.
Analysis Assistants: Help employees process large volumes of data, enabling more informed and accurate analyses.
Employee Training Tools: Enhance training by fetching relevant materials and providing personalized learning paths and real-time answers.
External RAG Use Cases
Customer Support Chatbots: Provide accurate and contextually relevant responses, improving user satisfaction and reducing the workload on human agents.
Public-facing Q&A Systems: Improve the accuracy and relevance of responses by sourcing information from trusted databases, enhancing user experience and trust.
Conclusion
The Retrieval-Augmented Generation (RAG) framework combines retrieval and generation processes, enhancing the accuracy, relevance, and personalization of responses. This leads to improved factual accuracy, reduced hallucinations, and increased transparency and trust. By leveraging relevant document retrieval and advanced language models, RAG significantly boosts productivity, analysis, training, and customer support within enterprises.
Looking ahead, the integration of RAG with generative AI in enterprises promises even greater advancements. As AI technology continues to evolve, we can expect more sophisticated and efficient RAG applications, further transforming how businesses operate and interact with data. This progression will likely lead to enhanced decision-making, more effective customer service, and overall improved organizational efficiency.
AnAr CITG – Innovating at the Intersection of AI and Real-World Applications

Explore the features of MSTest, NUnit, and xUnit: three leading unit testing frameworks that enhance your C# development process.

Organizations across the globe are increasingly turning to legacy modernization to keep pace with rapidly evolving business needs and stay ahead of…

In waterfall project management, software engineers create a feature and then throw it over to the quality assurance team (QA)…

Test and Operations (TestOps) is the emerging trend in testing. It introduced a newer technique of testing. This advanced testing…