Azure Data Lake is a scalable data storage and analytics service. The service is hosted in Azure, Microsoft’s public cloud.

We’ve been hearing a lot about the Microsoft Azure cloud platform. With all of the talk about cloud and the different Azure components available, it can get confusing. Large enterprise organizations are struggling with an ocean of data. From online shopping analytics to the Internet of Things (IoT) sensor data, the modern IT team is inundated with raw or semi-raw data captured from every side of the organization. These entities have begun dumping this raw data into a holding tank called the data lake until they can make use of all of the non-defined, schema-less information. Data that hasn’t yet reached its full potential can now be housed in Microsoft’s Azure Data Lakes, a robust cloud-driven repository for big data. In this blog, we check in detail what is Azure Data Lakes? How does it work? what are its parts etc
What Is A Data Lake?
- A data lake is a central storage repository that carries big data from many sources of raw data in its native form until it is needed.
- It can store structured, unstructured data, or semi-structured, which means data can be kept in a more flexible format for future use.
- A data lake is capable of Store and analyzes petabyte-size files and trillions of objects.
- It also Develops massively parallel programs easily.
What is Azure Data Lakes?
Microsoft Azure Data Lake is part of the Microsoft Azure public cloud platform, which includes more than 200 products and cloud services. Azure Data Lakes is a cloud platform designed to support big data analytics. It provides unlimited storage for structured, semi-structured, or unstructured data. It can be used to store any type of data of any size.
Azure Data Lakes is a suite of data services available in Microsoft Azure. Data Lake services allow businesses to store, analyze, and manage various forms of data of different sizes. Azure Data Lakes product suite provides access to multiple features, such as Spark, Storm, H-Base, U-SQL, and so on. Users can consider their own business requirements and pay as they go.
Advantage Of Azure Data Lakes
- Highly flexible and scalable as it is housed on the cloud.
- Allows streamlining data storage for all business needs.
- A huge amount of data can be processed simultaneously providing quick access to insights.
- Data Lake stores everything like multimedia, logs, XML, sensor data, social data, binary, chat, and people data.
- No limit on data storage and file size.
- Supports massive analytics workloads for in-depth analytics.
- It supports schema-less storage
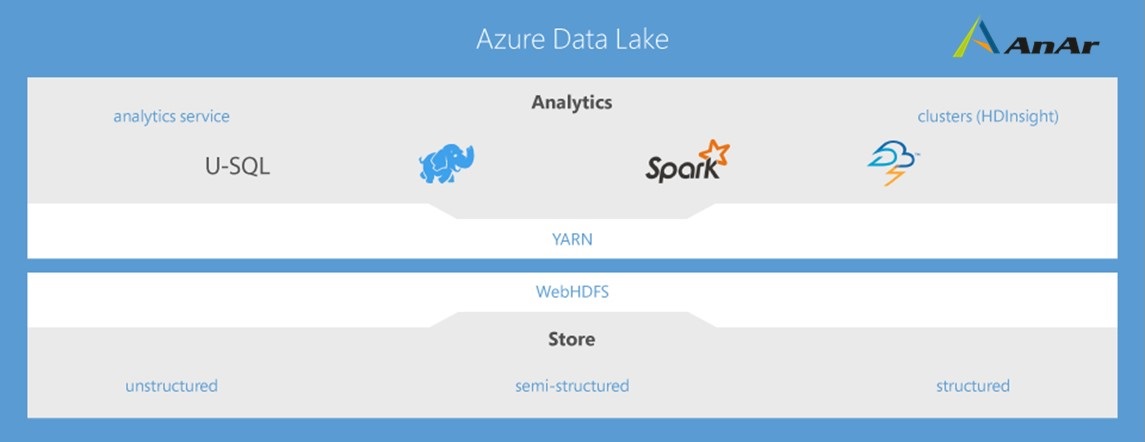
What are the Three Parts of Azure Data Lakes?
The full solution consists of three components that provide storage, an analytics service and cluster capabilities.

Azure Data Lakes Storage
Azure Data Lakes Storage is a massively scalable and secure data lake for high-performance analytics workloads. Azure Lake Data Storage was formerly known and is sometimes still referred to as the Azure Data Lakes Store. Designed to eliminate data silos, Azure Data Lakes Storage provides a single storage platform that organizations can use to integrate their data.
- It provides a single repository where small or large organizations upload data of just about infinite size.
- It is designed for high-performance processing and analytics from Hadoop Distributed File System tools and applications, including support for low latency workloads.
- It allows structured and unstructured data in their native formats.
- It allows for huge throughput to boost analytic performance.
- It offers high availability, durability, and reliability.
- Azure storage services are better than Amazon S3 because it gives an integrated analytics service and places no limits on file volume.
- Types of ADLS.
- ADLS Gen1.
- ADLS Gen2.
- Types of ADLS.
Azure Data Lakes Analytics
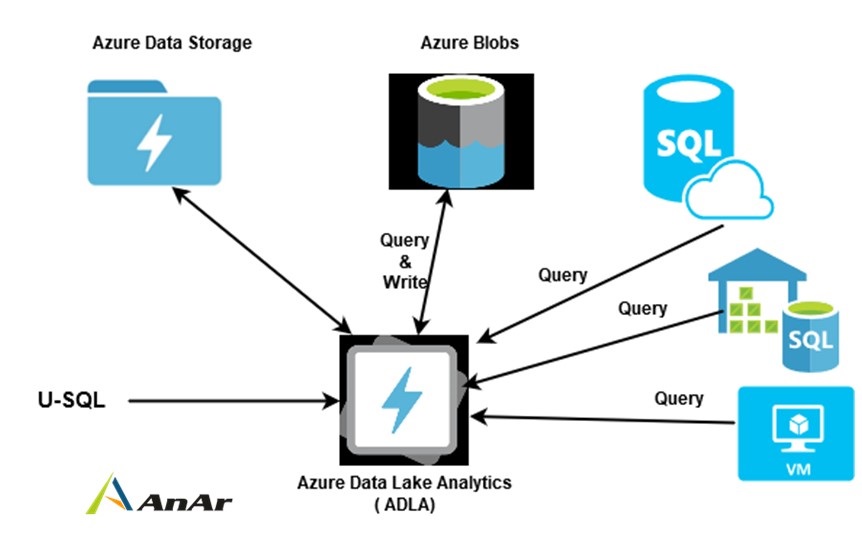
Azure Data Lakes Analytics is an on-demand analytics platform for big data. Microsoft Azure platform supports big data such as Hadoop, HDInsight, Data lakes. Usually, a traditional data warehouse stores data from various data sources, transform data into a single format and analyze for decision making. Developers use complex queries that might take longer hours for data retrieval. Organizations are increasing their footprints in the Cloud infrastructure. It leverages cloud infrastructure warehouse solutions such as Amazon RedShift, Azure Synapse Analytics (Azure SQL data warehouse), or AWS snowflake. Users can develop and run massively parallel data transformation and processing programs in U-SQL, R, Python, and .NET over petabytes of data. (U-SQL is a big data query language created by Microsoft for the Azure Data Lakes Analytics service.) With Azure Data Lakes Analytics, users pay per job to process data on demand in analytics as a service environment. Azure Data Lakes Analytics is a cost-effective analytics solution because you pay only for the processing power that you use.
The cloud solutions are highly scalable and reliable to support your data and query processing and storage requirements.
The data warehouse follows the Extract-Transform-Load mechanism for data transfer.
- Extract: Extract data from different data sources
- Transform: Transform data into a specific format
- Load: Load data into predefined data warehouse schema, tables
- Extract-Transform-Load mechanism
The data lake does not require a rigorous schema and converts data into a single format before analysis. It stores data in its original format such as binary, video, image, text, document, PDF, JSON. It transforms data only when needed. The data can be in structured, semi-structured and unstructured format.
Azure HDInsight
Azure HDInsight is a cloud-based service from Microsoft for big data analytics that helps organizations process large amounts of streaming or historical data.
Azure HDInsight is a cluster management solution that makes it easy, fast, and cost-effective to process massive amounts of data. It’s a cloud deployment of Apache Hadoop that enables users to take advantage of optimized open source analytic clusters for Apache Spark, Hive, Map Reduce, HBase, Storm, Kafka, and R-Server.
With these frameworks, you can support a broad range of functions, such as ETL, data warehousing, machine learning, and IoT. Azure HDInsight also integrates with Azure Active Directory for role-based access controls and single sign-on capabilities.
Microsoft promotes HDInsight for applications in data warehousing and ETL (extract, transform, load) scenarios as well as machine learning and Internet of Things (IoT) environments.
The fully-managed and open source service is based on the Hortonworks Data Platform (HDP) Hadoop distribution and includes implementations of Apache products, including:
- Spark
- HBase
- Storm
- Pig
- Hive
- Sqoop
- Oozie
- Ambari
HDInsight enables integration with business intelligence tools like Power BI, Excel, SQL Server Analysis Services and SQL Server Reporting Services. The service’s security measures for data include encryption, monitoring, virtual networks, Active Directory authentication, authorization and role-based access control (RBAC).
A few useful features of a data lake are:
- It stores raw data ( original data format)
- It does not have any predefined schema
- You can store Unstructured, semi-structured and structured in it
- It can handle PBs or even hundreds of PBs data volumes
- Data lake follows schema on the reading method in which data is transformed as per requirement basis
Are you interested in learning more about us and how we can give your business a competitive advantage?
Contact us to explore how a data lake can help your organization to realize the full potential of its data.



