In recent years, the adoption of microservices architecture has experienced a remarkable surge in popularity, emerging as a sustainable alternative to traditional monolithic systems and service-oriented architectures. This architectural approach entails decomposing complex applications into smaller, loosely coupled services, each focused on a specific business capability. By embracing this modular and distributed design, developers are able to create scalable and resilient solutions that can adapt to evolving business needs.
One of the key advantages of microservices architecture lies in its ability to enhance the speed and performance of applications. By breaking down the application into discrete services, developers can individually optimize and fine-tune each component, resulting in improved response times and overall system efficiency. However, achieving these benefits requires a deep understanding of the common challenges and patterns that arise when working with microservices.
Even experienced professionals may encounter difficulties when adopting a microservices architecture. The complexity of managing a distributed system, ensuring inter-service communication, maintaining data consistency, and orchestrating service discovery can pose significant challenges. To address these challenges, two key approaches have emerged as solutions: Microservices CRUD and Microservices CQRS.
Comparing CRUD Vs. CQRS:
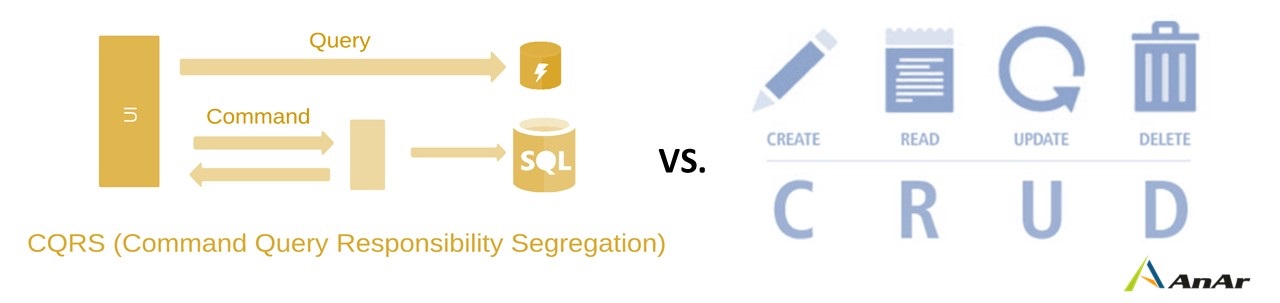
Create, Read, Update, and Delete (CRUD) and Command and Query Responsibility Segregation (CQRS) are two of the most common microservices development patterns for dealing with data manipulation.
CRUD model exists for years, and a huge number of software systems have been built by combining CRUD & validation. Frameworks provide the same pattern across applications of List, select, view, delete and validate.
In conventional data manipulation applications, CRUD architectures are unquestionably the most popular. One of the main benefits of this architecture is its simplicity; all operations are performed using the same set of classes. CRUD is more of duplication as only the fields change. The request for create, read, update, delete will look the same. You will find yourself doing same thing several times.
CQRS (Command Query Responsibility Segregation) works with queries and commands. The queries return some result keeping the state of an object unchanged. The commands change the state of the object but do not show the result. CQRS is infamous as complex in implementation which is not the reality.
CQRS allows you to create REST based services in just a few minutes for Windows 8 applications, iOS, and Android phones. CQRS uses different models to read and update information, which outspreads the level of complexities.
Once you create, update, read or delete records, the aim is to store the interactions making the data retrievable. Need may arise to record the information in different ways. E.g., based on validations and combining information received from different sources.
If your structure has multiple layers of representation, it can get pretty complex. The remedy is to narrow it down to a single conceptual representation to act as the conceptual integration point between all presentations. Maintaining consistency in separate object models is a bit difficult.
Ideally, CQRS should be used for some portions of the system that will ease handling of complex domains. Using CQRS can increase risks and reduce productivity if it is not in concurrence with the domain. For domain conflict issues and challenging queries, you can use Reporting Database. CQRS does not restrict you to have a single read data store in your model. Based on the features of the application, you can create one or multiple data stores, each one implemented for specific use. This is needed as the application uses same subset of information in a number of ways.
Microservices Development Patterns CRUD Vs. CQRS:
There are several patterns out there for handling data in microservices development. The most familiar one being the CRUD pattern.
The CRUD pattern fundamentally models our service operations by emulating the operations performed on our data store. As the service interface, we can present these operations directly. This pattern is best suited for simple business domains with few complex relationships between domain entities and their operations.
Event Sourcing: It is for accumulating events that take place in our system. Event sourcing is commonly used with CQRS as they complement each other. The limitation is that it does not record the latest status of record.
To provide the response to the query for final status, the system has to merge the existing event information. This will slow down the results compared to traditional methods where data is ready and just pulled to display. This issue can be solved by re-creating the asset every time it is changed and filter it using CQRS.
Assume the event writing as a model and reading model as the final state. When the client changes the state of the asset on the system, the event information is generated. As the outcome of the operation stores in system as the model for writing.
The audit trail can help us to know what was changed and when in the database. Auditing is a must as you do not have the history of updates or the source.
Strong Consistency: Most of the database developers are aware of this model. Since it bears similarity to the conventional transaction model with properties such as Atomicity, Consistency, Durability (ACID) and Isolation. The changes in any node necessitates consensus among all nodes before the new value is available for client reads. The candid requirement is to block all the nodes till they converge. Actually, depending on network latency and throughput can be problematic.
Applicability: Though there are exceptions, but the ultimate truth is that consistency is preferred in scenarios where availability and throughput are far more relevant than instantaneous consistency. A majority of businesses have applied some level of eventual consistency. It is human tendency to look for the latest updates as they are interested in the newest information and want to understand it in a short span.
Basic Differentiation CRUD Vs. CQRS
| Focuses | CRUD | CQRS |
| Model | Traditional approach to models | Traditional and modern approach to models |
| Ease | It is quite easy to pull CRUD instances out of the assembly line | Easy enough to add Event Sourcing or a reporting database. |
| Dataset | Any type of dataset but large database can add to the complications | Preferrable for but large database having multiple tables to tackle complexities. |
| Type of Applications | Not suitable for complex applications, best suited for simple business domains that have few complex relationships between domain entities & its operations | Suitable for complex applications, best suited for classified business domains that have complex relationships between domain entities & its operations. |
| Supports Languages | Java, Javascript, PHP, Perl, Python, .NET, Ruby, SQL | Ballerina, C#, F# |
Developer’s point of view CRUD Vs. CQRS
| Concerns | CRUD | CQRS |
| Code | Coding is simple but repetitive | The code is simple and easy to understand and maintain but requires more and more code in form of new classes. |
| Quickly Create | Applications having multi-users and extensive implementation | Event based programming models. |
| DDD | DDD or Domain-Driven Design lets you set priorities to focus on business model | Does not integrate well with Domain-Driven Design approach in applications. |
| Update | Update is immediate hence changes are visible without delay | CQRS takes time to display the change made to the database as the read and write model needs time to synchronize. The user needs to refresh the page to view the change. |
| Update | Cannot isolate the read and write models to handle them separately | Read and write model cannot be updated simultaneously else you may face performance issues. |
| Testing | CRUD testing is database/ black box testing | CQRS testing is behavioral testing based on object’s behavior without considering its state. |
| Data Model | CRUD uses same data model | CQRS uses separate data model |
| Commands | Commands should be processed simultaneously | Queued commands are not to be processed simultaneously |
Impact on Business Applications CRUD Vs. CQRS
| Matters | CRUD | CQRS |
| Design & Implementation | Single model is great to address simple problems | Separate query and update models streamlines design & implementation |
| Independent Scaling | Not possible as single data store handles all CRUD operations | The read and write workloads can scale independently |
| Unique Points | Same strategy is used repetitively | Apply different optimization strategies to read and write |
| Valuable Insight | How you query your data is not much different from the way you manage, update, and manipulate data. You can create view based on single and multiple base tables. Can perform DML operations is view is single based table. | How you read and query the data is probably very different from the way you manage, update, and manipulate data. |
Conclusion: Microservices CRUD Vs. CQRS
Plan out the microservices within the context. Concentrate your efforts on solving problems that you build the software for without sticking to development patterns for the love of CRUD or CQRS. Admire the qualities of CRUD Vs. CQRS, feel free to develop applications in combination to create excellent solutions.



